Just the other day, fellow Filipino librarians were posting in Facebook posts about Internet Archive Scholar. As described in the post, Internet Archive includes fulltext search index of over 25 million research articles and other scholarly documents preserved in the Internet Archive. The collection spans from digitized copies of eighteenth century journals through the latest Open Access conference proceedings and pre-prints crawled from the World Wide Web.
One feature or system preference in Koha ILS that I feel not tapped by most Koha ILS libraries is this Global System Preference OPACSearchForTitleIn or More Searches option. This was blogged in Bywater Solutions website way back June 13, 2017. It was also blogged in listechnology wordpress.
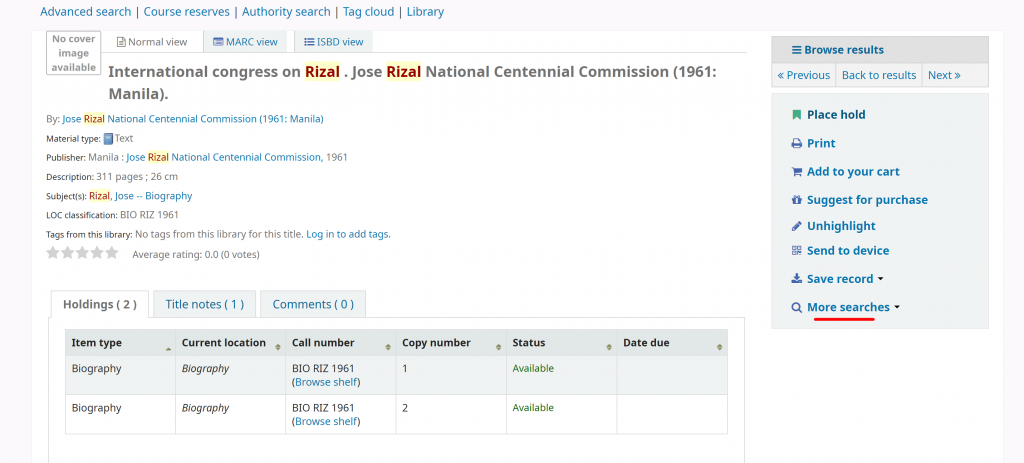
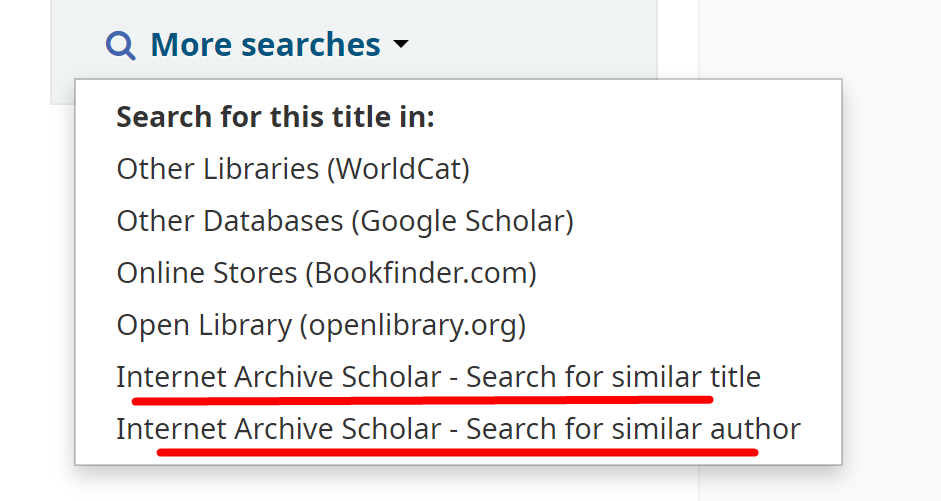
This feature can be accessed when you are in the bibliographic details of a particular material. It can be seen in the lower right sidebar as demonstrated below.
Default installations include four popular library databases: Worldcat, Google Scholar, Bookfinder.com and openlibrary.org
In fact, we can add more databases here, we just have to know how searching works for a particular database we want to add. This is documented in the Koha documentation, the “OPACSearchForTitleIn” part. The Bywater Solutions tutorial too described how to edit this System Preference.
So this tutorial will guide you through on how to add this html line in order to add More searches for Internet Archive Scholar. Here are the steps:
We go to our OPAC System Preference (Koha Administration > Global System Preference > OPAC > OPACSearchForTitleIn.
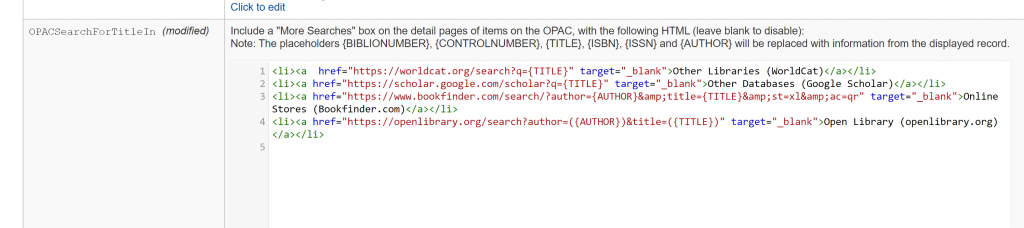
Click the “click to edit” under OPACSearchForTitleIn to expand the text box
The default for OPACSearchForTitleIn
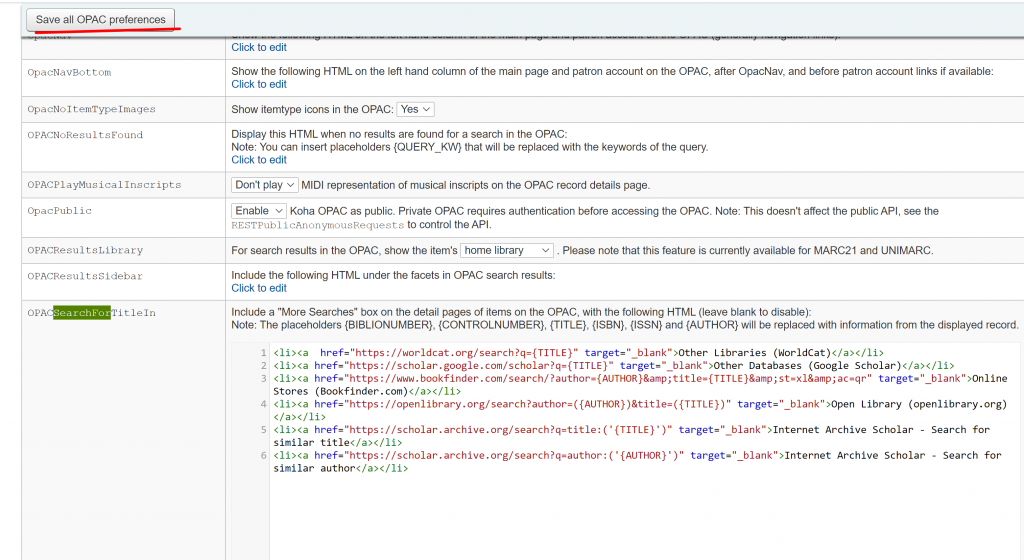
3. We add the following lines below the block of lines already present in OPACSearchForTitleIn:
<li><a href="https://scholar.archive.org/search?q=title:('{TITLE}')" target="_blank">Internet Archive Scholar - Search for similar title</a></li>
<li><a href="https://scholar.archive.org/search?q=author:('{AUTHOR}')" target="_blank">Internet Archive Scholar - Search for similar author</a></li>
We click save all OPAC preferences to save what we have added.
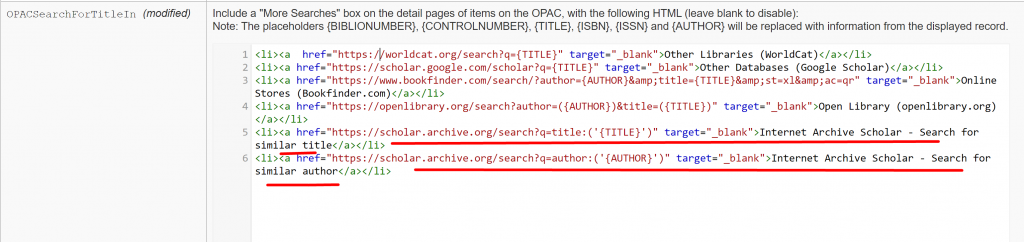
These two html lists are actually title and author searches in Internet Archive Scholar and these are now added into our OPAC’s more searches.
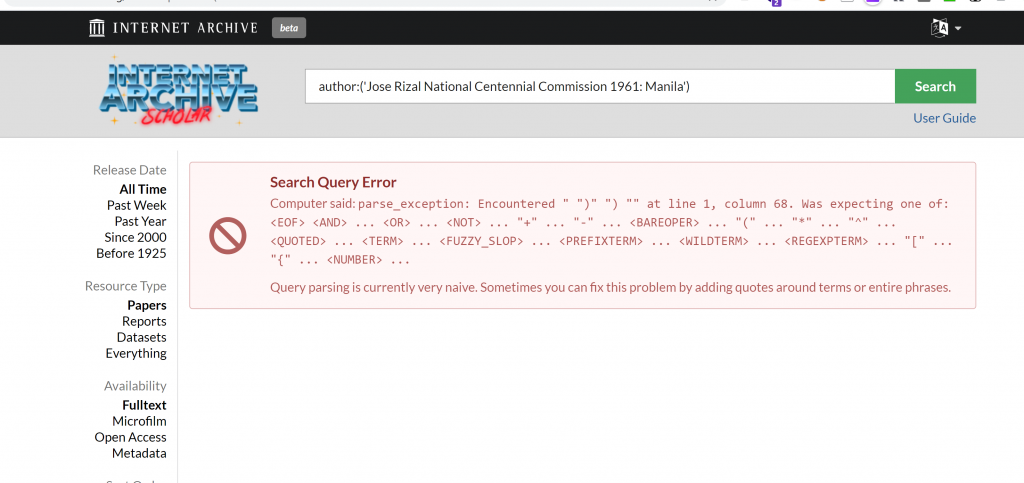
4. But that’s not all, we have to add a jquery into our system preference or else we will get the following error below if our main entry/author is a Conference Name.
We are getting this error because of the extra open and close parenthesis in our main entry. So how do we solve this?
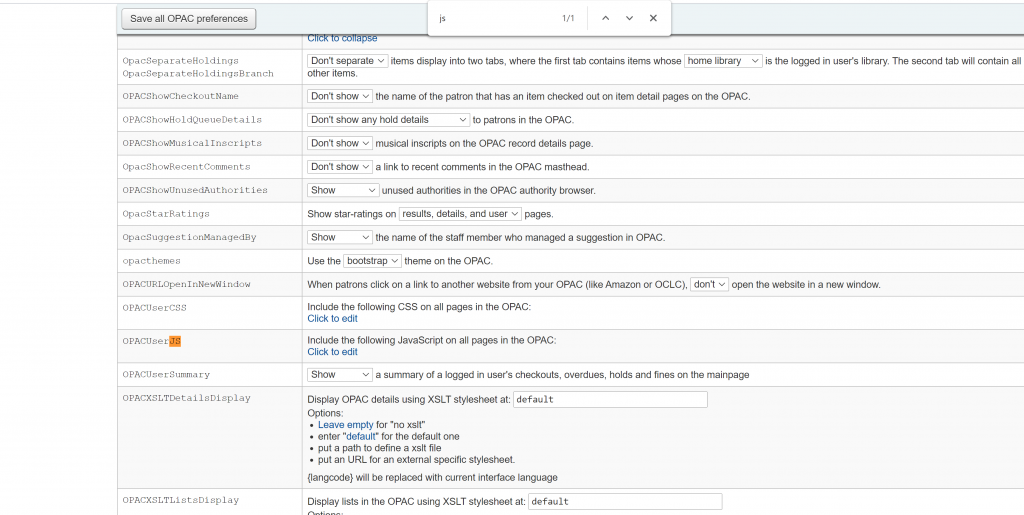
Still the OPAC System Preference, we search for OPACUserJS
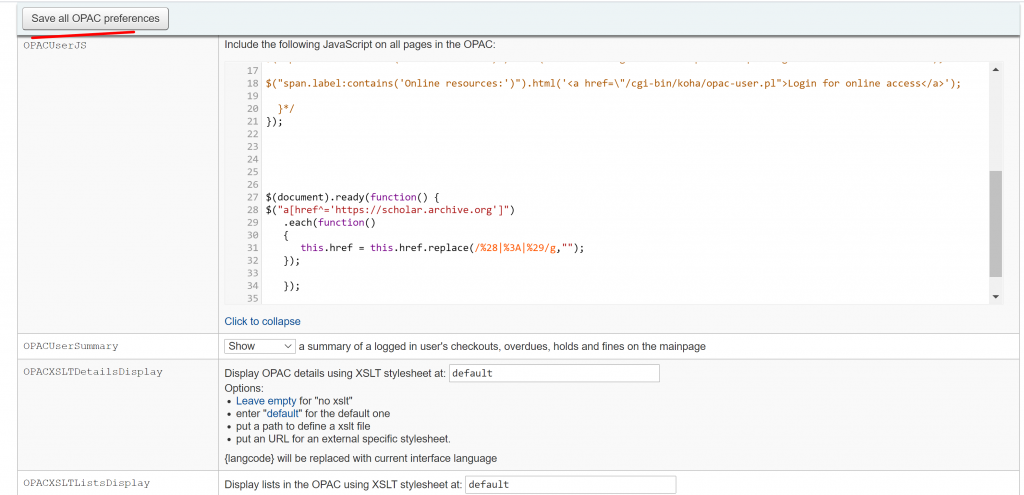
Click the OPACUserJS part to edit it. At the bottom of the textbox, we add the following codes. Just in case this part of your OPACUserJS has a lot of stuffs in there, back it up first by copying the line of codes and pasting it to your favorite notepad of choice for saving the backup.
We now have a working Internet Archive Scholar More searches in our Koha ILS.
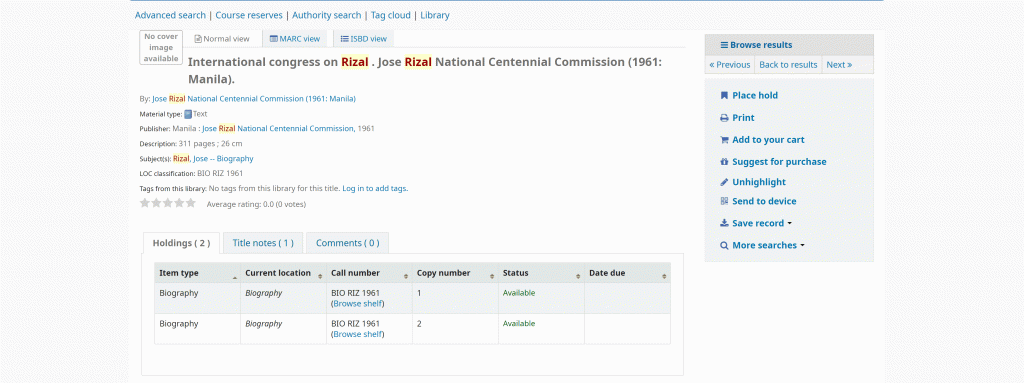
Pardon the made gif above, the sample search query I have is a conference name Jose Rizal National Centennial Commission 1961 Manila hence no search result. Basically, what is being passed in the search query is whatever is the metadata of your Koha ILS.
Useful Resources/References:
call, R., & Hochkins, S. (2021). Replace multiple characters in one replace call. Retrieved 9 April 2021, from https://stackoverflow.com/questions/16576983/replace-multiple-characters-in-one-replace-call
contains, j., Ball, M., Armstrong, C., & Ismail, A. (2021). jQuery: If this HREF contains. Retrieved 9 April 2021, from https://stackoverflow.com/questions/6374682/jquery-if-this-href-contains
Global system preferences — Koha Manual 19.11 documentation. (2021). Retrieved 10 April 2021, from https://koha-community.org/manual/19.11/en/html/systempreferences.html#opacsearchfortitlein
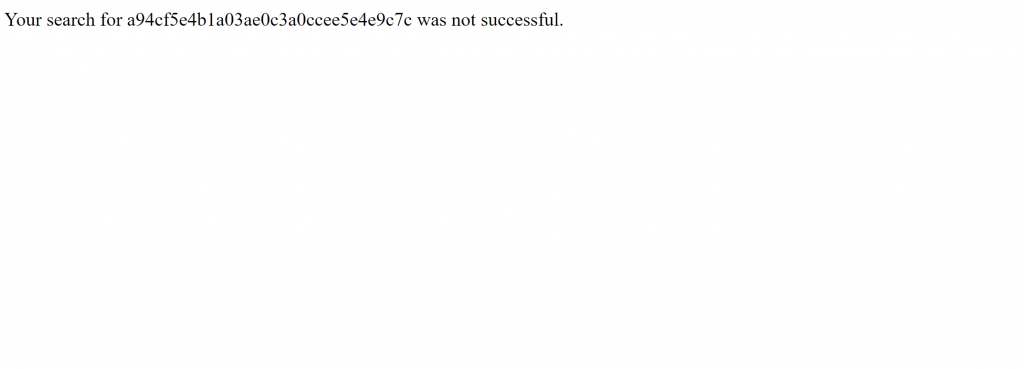
I previously blogged about how to refer uploaded files in Koha ILS here but the other day, I was at my wit’s end why I can’t access this recently recently uploaded file, I am getting this message prompt: “Your search for longHashNameHere was not successful”.
And so I looked at the opac-error.log and saw this line:
opac-retrieve-file.pl: Use of uninitialized value $isdirect in numeric ne (!=) at /usr/share/koha/opac/cgi-bin/opac/opac-retrieve-file.pl line 45
Looked at the opac-retrieve-file.pl line 45, we have this line of code:
if($isdirect != "1"){
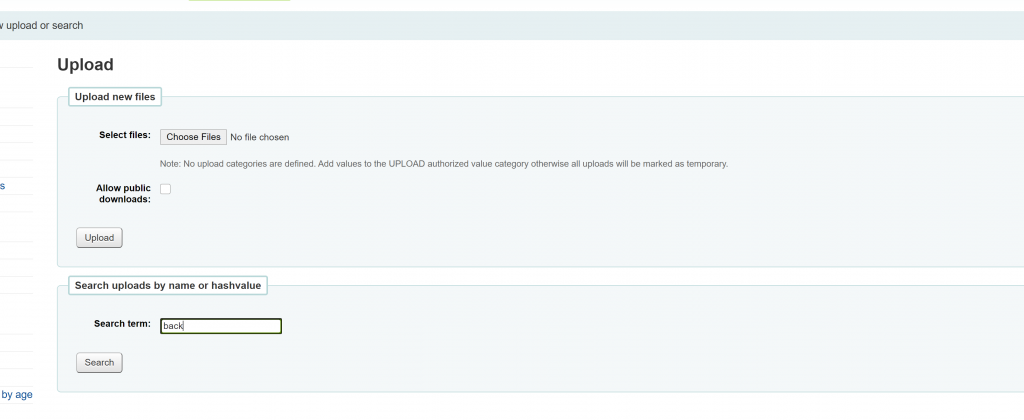
Further looking the lines before it, there is this line on public. Going back to my uploaded file by searching it in upload tool:
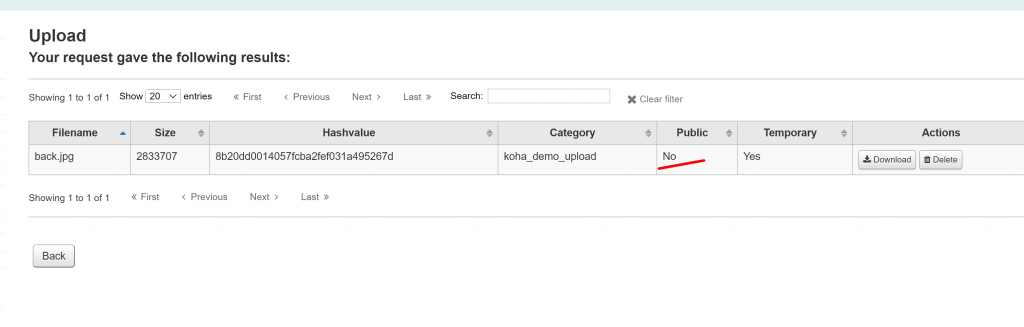
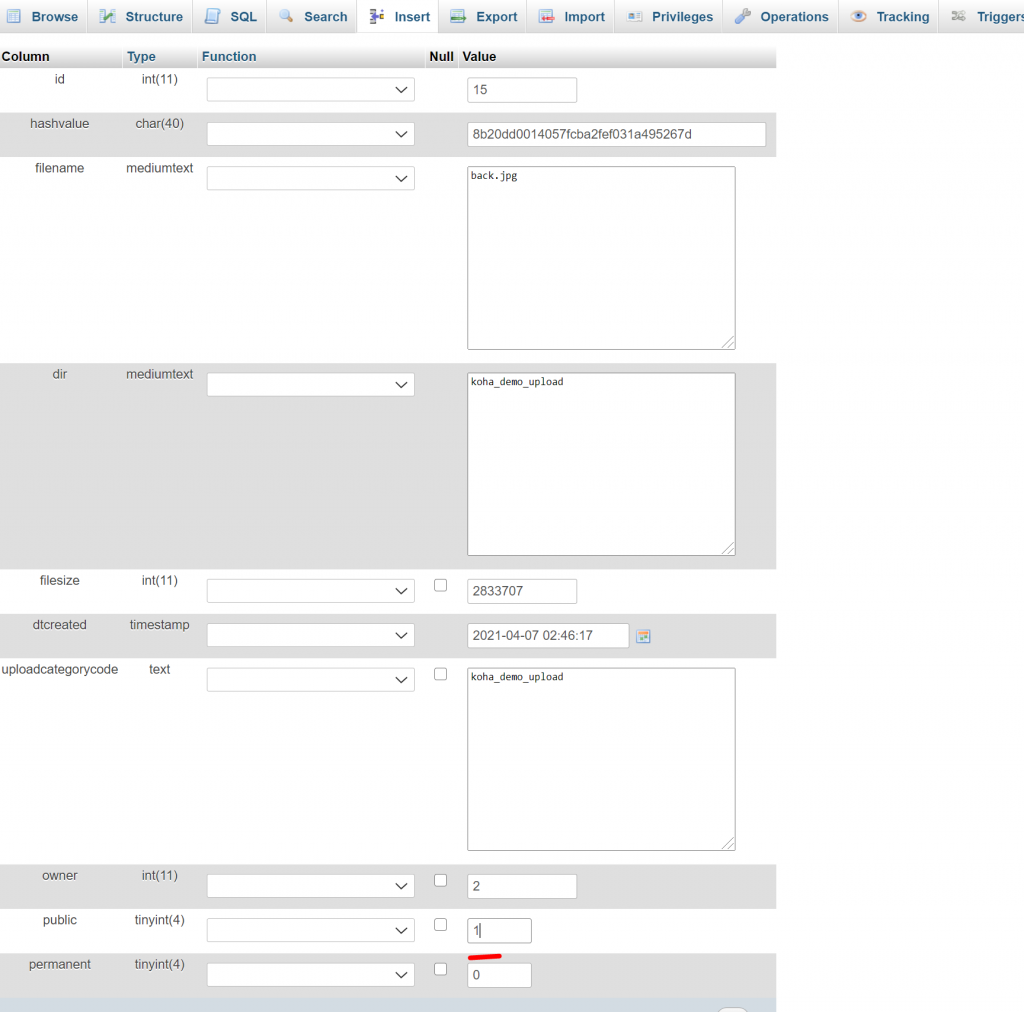
It turned out, the file isn’t public. Currently (I’m using 19.11.x), there is no way to edit this particular parameter so I had to do this in the mysql backend. Table is “uploaded_files”.
From this....to this. Notice I changed zero (“0”) to 1.
If it’s the first time you will be editing this one, you will get NULL value in public column/field. Since I already edited this part for the purpose of demonstrating it, the value is zero (“0”). Once the value is changed, I am now able to refer that uploaded file in the img src script which I previously blogged here. I have already updated also the blog entry to reiterate that the file should be public.
That’s all, I hope that if you were able to come here due to similar issue, it has helped you resolved your issue. Thanks for reading!
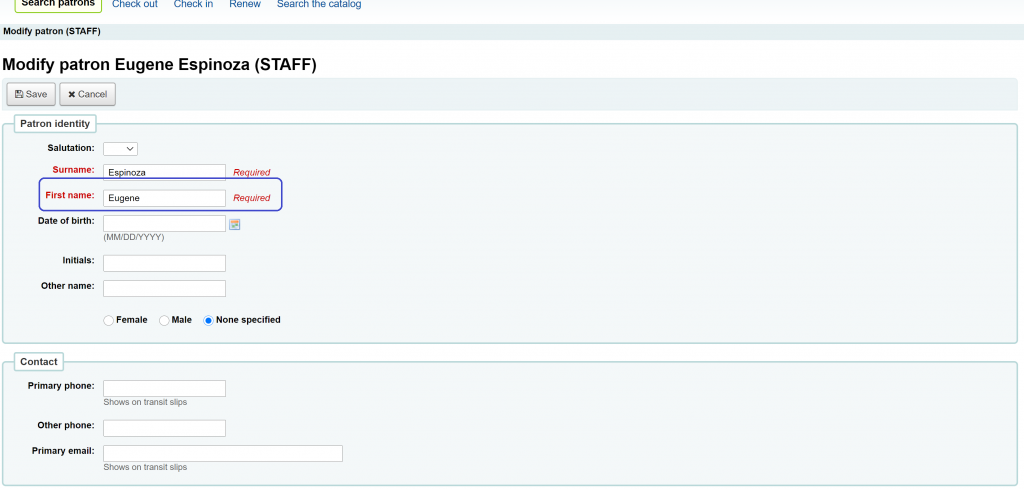
Just the other day, a Koha instance was migrated into one of the servers I co-managed. A patron was added in the ‘Patrons’ module but we were missing the ‘First Name’ field. So what happened? Why is the ‘First name’ field missing in the ‘Add patrons’ workflow of our Patrons module?
This got me digging further into this Koha ILS instance. I took a look into the ‘Edit patron’ workflow, I am also missing the ‘First Name’. Hmmm.. So I headed into the log, I might be able to capture any errors in there, but to no avail. I googled “Koha patron module missing first name field”, first page did not gave me any answers. Went to the ‘Global System Preference’ for Patrons and even edited the ‘BorrowerMandatoryField’ and added ‘firstname’ in there. Checked that ‘firstname’ is not included in the ‘BorrowerUnwantedField’ setting. But still I am not getting the Firstname field!
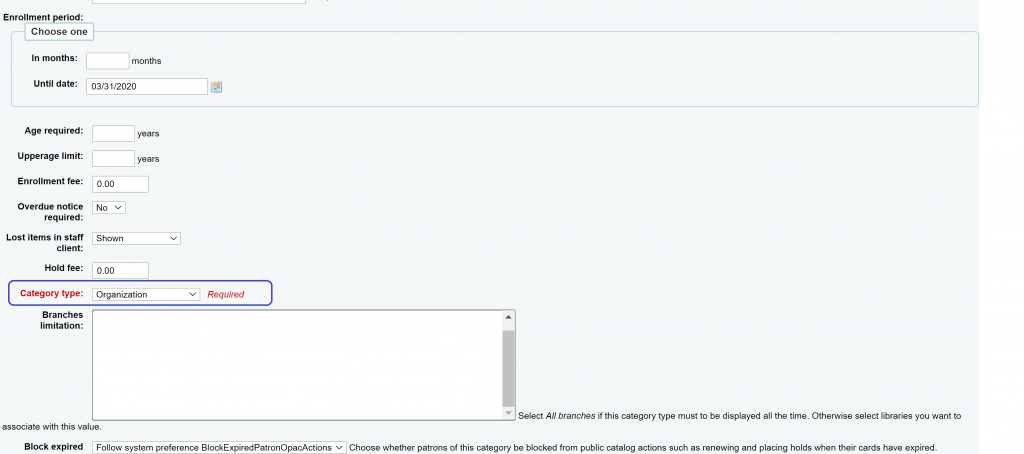
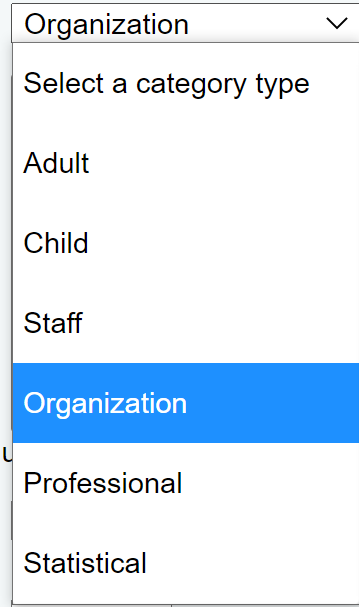
So off we went to that Patron category and looked at the settings until we saw the category type was set to Organization for our ‘ADMIN’ Category.
So, we tried changing this from ‘Organization’ to ‘Staff’ and went to the ‘Edit patron’ workflow of the Patrons module and Voila! The First Name field shows up in our interface! Problem solved!
Going to the Koha ILS manual (19.11), I don’t see in Patrons and Circulation > Patron categories a caution for using Organization as ‘patron category’ type. I don’t see this also in the Patrons module documentation. With this being said, I will try to contribute this part in the Koha ILS documentation so that the Koha ILS documentation will have that notification or caution for current and future Koha ILS users. That’s all and thanks for reading!
Just the other day, I was trying to get my hands dirty with Koha testing docker. Thanks to two wonderfully uploaded videos from Bywater solutions, some readings in the Koha wiki re: development as well as some help from Koha community IRC, I was able to push that first patch into the Koha ILS bugzilla.
Here are the pertinent resources that help me with my journey:
The Git book which can be accessed in this URL. Learn how to use Git from this resource. I’ve only read only until Chapter III but it basically helped me move forward with what I want to do in Koha ILS development. This was my starting point in understanding Git. I was able to try Git from way back for testing Github. This book was kind of refresher and the launching pad for what I have to do.
Various wiki sources from Koha ILS Community: a. Koha Community’s page about “Get Involved – For Developers” – Contains all the links on what we need in order to start submitting patches. b.Version Control Using Git – This reinforced what had been discussed from the Git book. But from here I got some clues like I have to clone the public repository as well as how to commit files. c.Coding Guidelines. d.Developer handbook. e.Git bz configuration – The part where submitting of patch is taken care of by Git bz. Installation of this has already been taken care of by the Koha Testing Docker and it will just be a matter of updating some parameters to be able to submit patches to Bugzilla from git.
Two youtube videos from Bywatersolutions a.Koha Testing Docker – Jessie Cairo (jz) was walk through by Kyle Hall (khall) and Nick Clemens (kidclamp) on how to install Koha Testing Docker in Mac. We were missing some parts in the video since khall and kidclamp already configured jz’s machine, but I guess the part was where they git cloned the Koha ILS repository. b.Koha Virtual Hackfest – Code Spaghetti streamed live on March 27, 2020 – Here, you will see Nick and Kyle get their hands dirty squashing bugs and go through how Koha ILS development is done.
Nos. 4 and 5 should actually be done before installing Koha Testing Docker. I cannot find the resource I used for installing Docker Compose but a simple google search like “Install Docker Compose Debian 9” will lead you to the right direction on how to install Docker Compose but mine is like below:
#Install curl if curl is not yet installed
apt-get install curl
#Install docker - docker.com:
curl -L "https://github.com/docker/compose/releases/download/1.23.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
I won’t go into details on the process but if you take a look at the resources I mentioned in nos. 1-4, those will help you a lot in going to Koha ILS development for newbies in going through Koha ILS development process. And as addendum to the resources above, I will add no. 6 below as resource the chat in IRC:
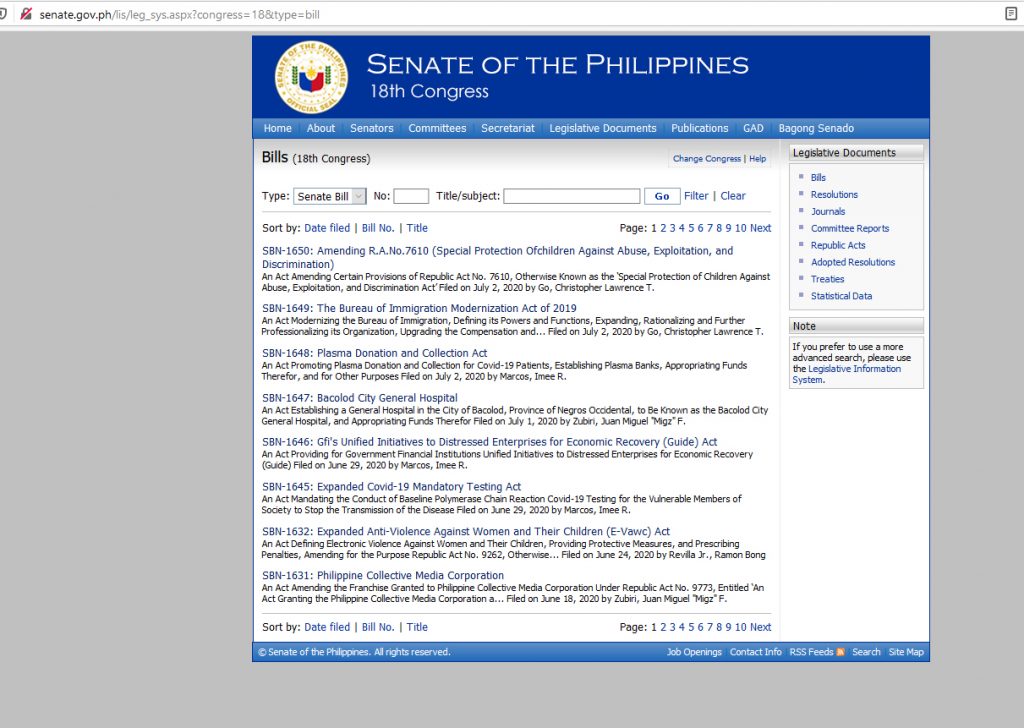
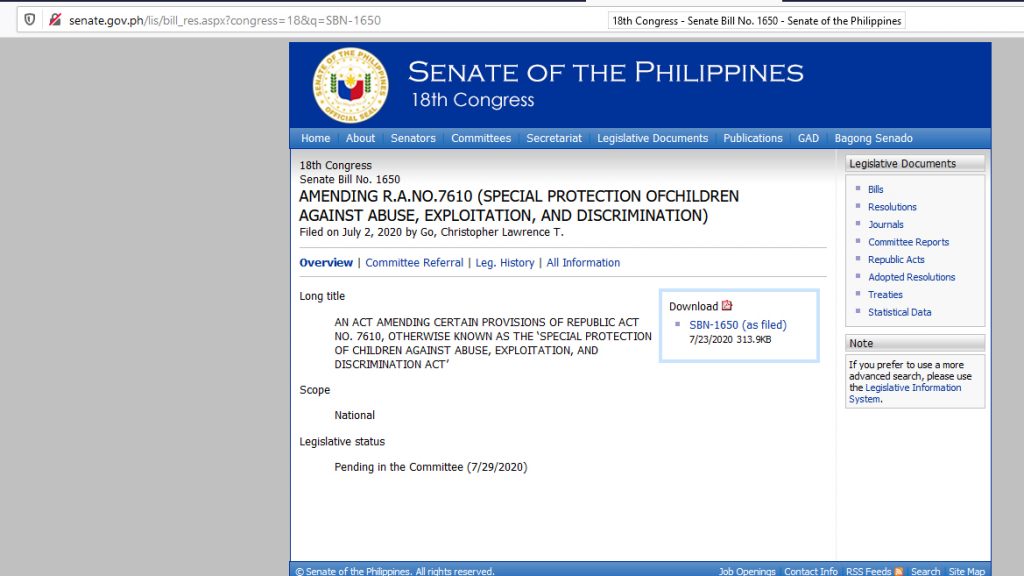
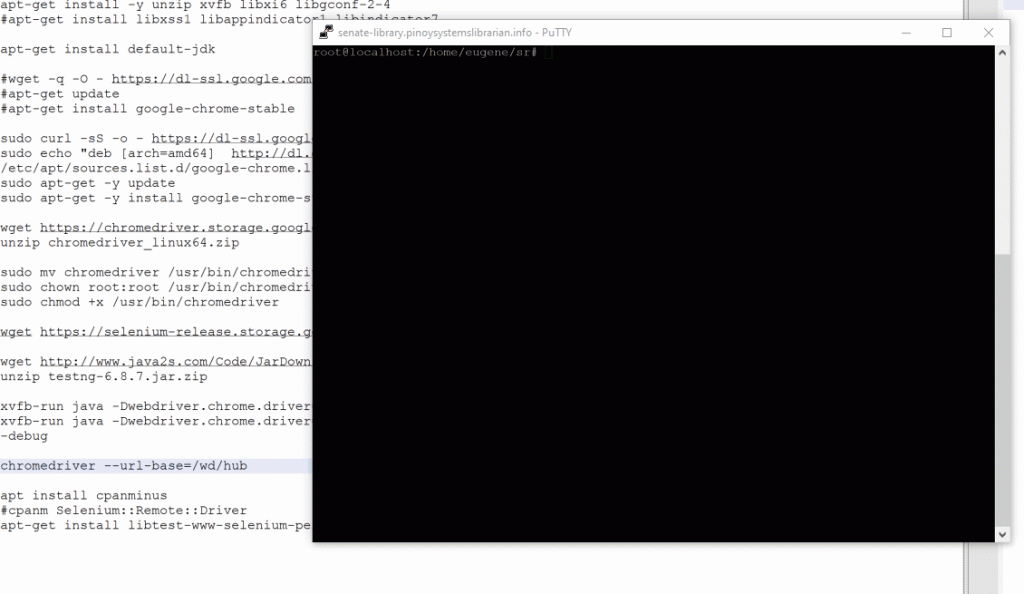
Just the other day, I was trying out Selenium for a project I am doing for the Senate Library. Since I was having a hard time curl-ing lists of URLs and consequently automating download of certain parts of html files available at the Senate Legis. In this case, Senate Bills available here
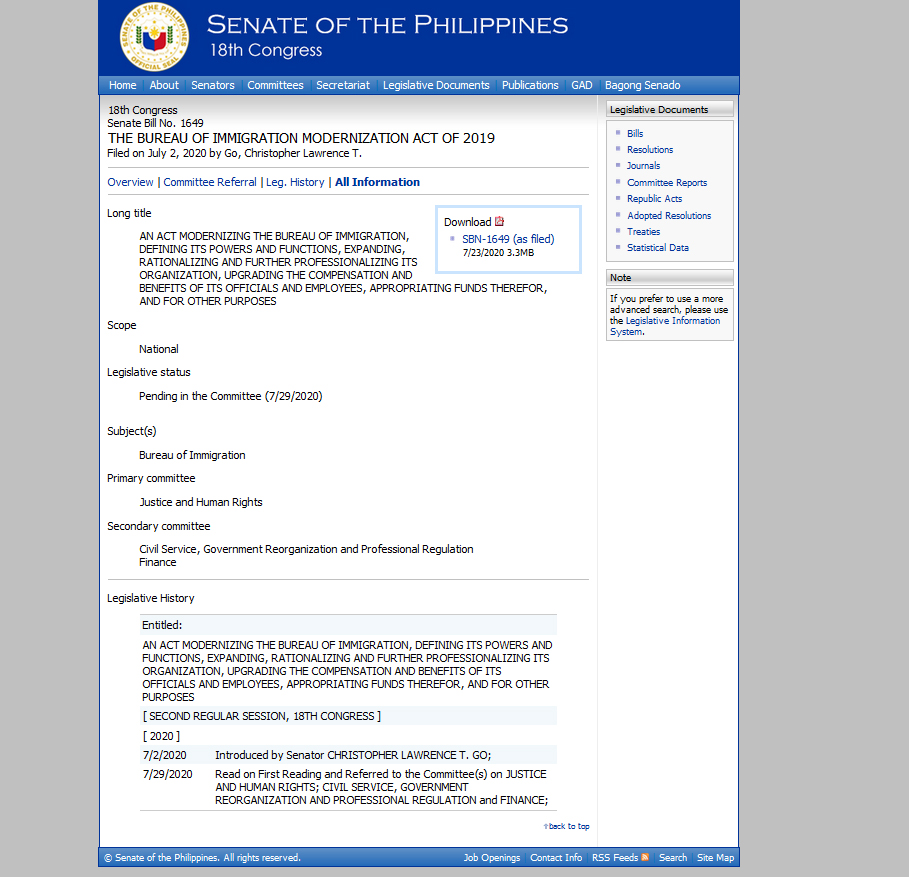
The image above is only the “Overview” of a particular bill, but I am actually more interested in “All Information” which you can see is in the fourth row, just right after Leg. History. As you can see in the image below, it has more information about the Bill and that is what I wanted to capture and repurpose in a different database.
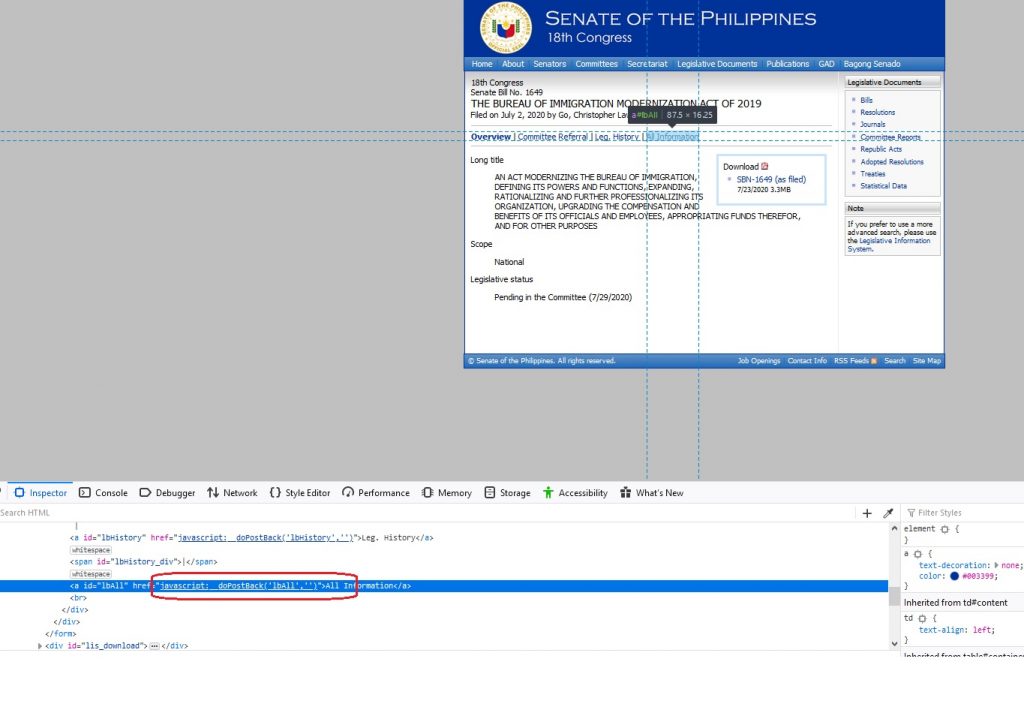
I can actually easily do a perl program with curl that does something like “Go through a list of URLs, after which the program goes to the “All Information Link” and lastly download the html file that includes all web elements in “All Information”. However, there was a problem. Apparently, the link for “All Information” is controlled by a javascript. After researching on how to go about this, apparently I can not do that, and one answer in one stackoverflow question I chance upon suggested using Selenium. And so my adventure with started.
After reading about Selenium and what it can do, I was convinced that this is the way to go about this project. For starters, and based from its main website, Selenium automates browsers.
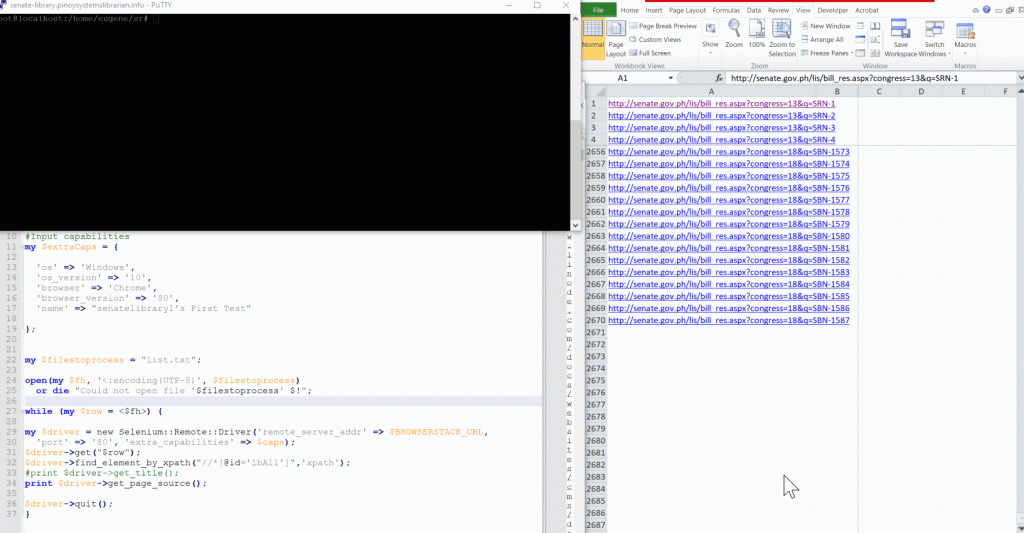
To get my feet wet, I first tried Browserstack‘s free trial and reading through its documentation on perl, I was able to make it work a small snippet of code from Browserstack. You can see it in action in gif file below.
But the problem with Browserstack is that the free trial is only good for 100 minutes. I have 12670 URLs to run through and three accounts with 100 minutes each (for a total of 300 minutes) won’t make the cut. So, what I did is try to install Selenium in a server*. There is this easy install Selenium available in github created by ziadoz so for the Selenium stack that’s what I installed. I also installed Selenium::Remote::Server module so that I can use selenium for Perl but first installation of this module was not breeze and I cannot remember how I was able to successfully install this module, a separate blog will be created instead on this.
Only then did I realize that the chrome that I should be trying to run for my perl script should be headless since I am using a headless server. My Selenium server as well as the Chrome driver starts properly in the command line. I adjusted the variables in my perl file and I was getting sorts of error. And the last error that I had was like below:
Could not create new session: unknown error: Chrome failed to start: exited abnormally.
(unknown error: DevToolsActivePort file doesn't exist)
(The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)
Lo and behold after adjusting my code and added that chrome option headless did my script run properly.
*Full installation procedure to be posted in a separate blog.
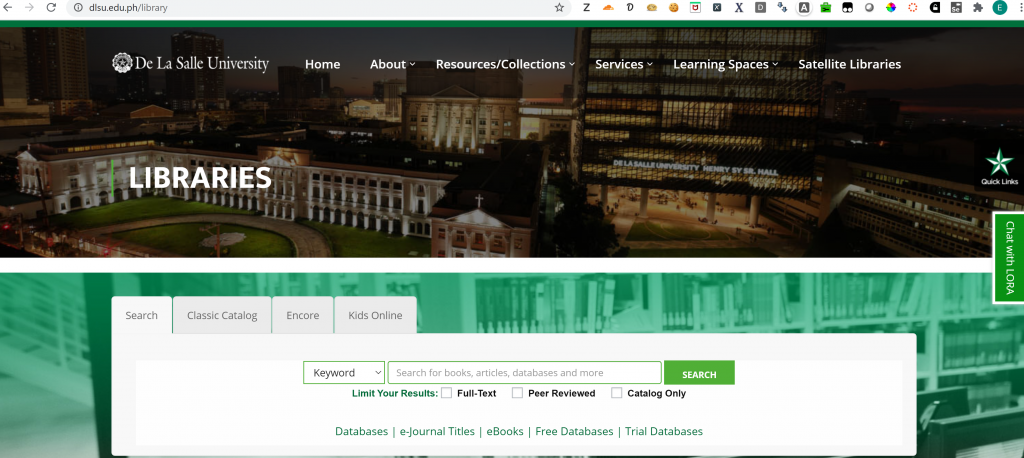
Just the other day, just when I thought the DSpace search form I did for a WordPress project works perfectly, it actually wasn’t! So I had to inspect and investigate more on how DSpace search works. You can actually create search forms in your content management system or any system that accepts any web-based technologies (HTML, css, javascript, jquery) just like these search forms in De La Salle University Library‘s home page
We can see in the home page the following tabs: Search, Classic Catalog, Encore and Kids Online. The Search tab is the main Search tab which utilizes EBSCO Discovery Service. The second tab is for the Millenium ILS Library Catalog. The third tab is for the Millenium ILS Encore while the fourth is for “Kids Online”. These search forms were actually done by yours truly while still working as Systems Services Librarian with the De La Salle University Library. I’m not gonna go in detail but those who wanted to achieve similar search forms should look into html forms and this nicely published blog by Birmingham Young University on Understanding HTML Forms and GET and POST methods as well as this w3schools post on HTTP Request Methods. The main ingredients for such are the following:
form tag with the corresponding action value or a javascript function that will further process the input into the form;
select options that will act as delimiters for your search;
Optional hidden inputs that has name value pair that you can inject into your form;
input for the text/query to search;
The submit button/input that will process the form.
Now we go to DSpace. Keyword search in DSpace can be executed site-wide in the search box located in the upper right hand side of the DSpace Institutional Repository. Site-wide meaning all collections will be search in this search box. And please also note that this use case is for DSpace that utilized Mirage2.
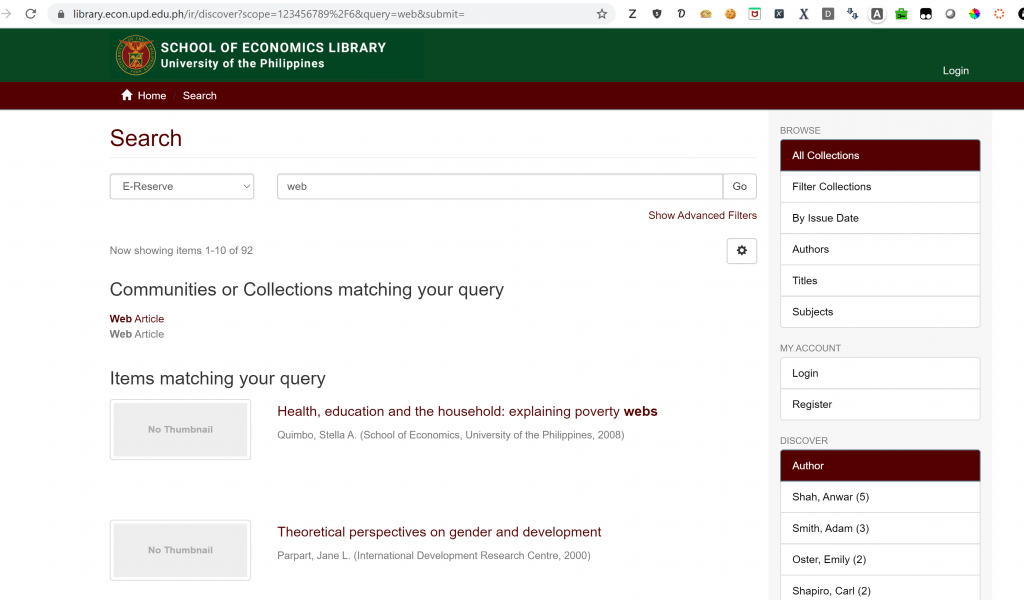
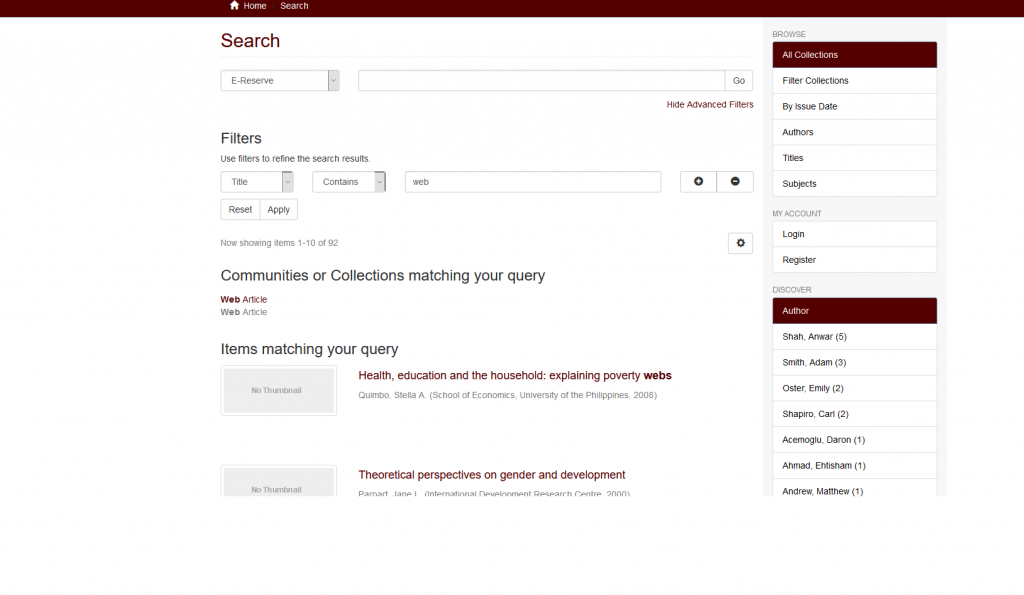
If we dig deeper on our search and search a particular Community (in my case E-Reserve).
DSpace Search filter by Community
We can see that the URL fragment for my Community (e-reserve) is like below: https://urlofmydspace/ir/discover/?scope=12345678%2F6&query=web&submit.
Let us dissect the URL fragment one by one.
https://urlofmydspace – This is the Domain name of my DSpace.
ir – This is the directory DSpace under the domain https://urlof mydspace
/discover – Together the two abovementioned in direct order, this is the link for the DSpace search.
? – The question mark is the start of the query string of our GET request (form)
scope=12345678%2F6 – name/value pair for our collection.Name here is “scope” and the value is 12345678%2F6, %2F here is the special character “/”, “thus 12345678/6”
& – separators for our name/value pairs
query=web – This is the name/value pair for our query.
submit – This last part can actually be omitted when constructing our search form
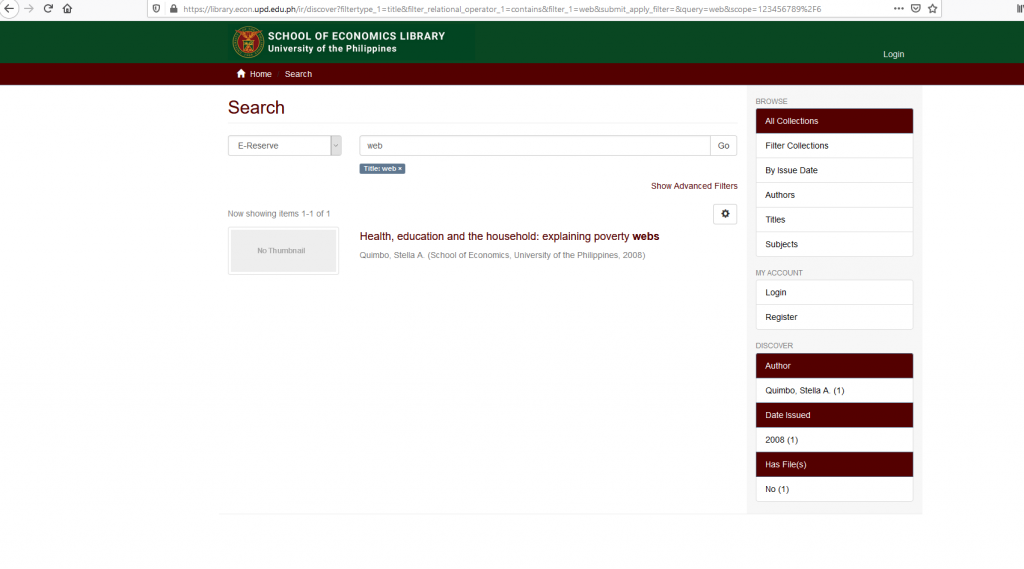
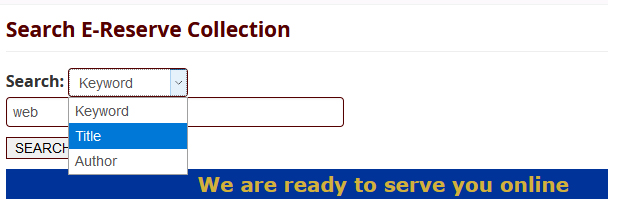
So when constructing our search form we take into consideration the abovementioned “name/value” pairs. But we will have a problem if we further filter our search to Title and Author. If we search for title by clicking the Show Advanced Filter in the DSpace interface like below.
DSpace search filter
By choosing Title in the dropdown and add our search term in the search box, leaving the default “Contains” filter, and clicking the “Apply” button, we will get the following search result.
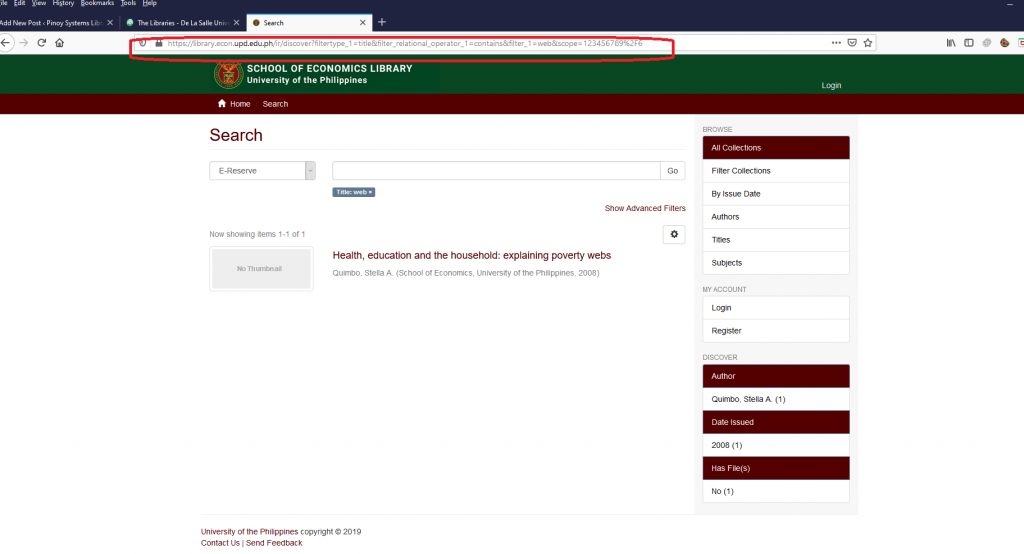
And we will see here a more complicated URL fragment: https://urlofmydspace/ir/discover?filtertype_1=title&filter_relational_operator_1=contains&filter_1=web&submit_apply_filter=&query=web&scope=123456789%2F6
Let us dissect the URL fragment for search filtered by “Title”. But let’s focus on this string ” filtertype_1=title&filter_relational_operator_1=contains&filter_1=web&submit_apply_filter=&query=web&scope=123456789%2F “
filtertype_1=title – This is the name/value pair for filtertype_1 “title”. For author filter, this will become filtertype_1=author
filter_relational_operator_1=contains – This is the “Contains” filter, the dropdown after our filtertype_1
filter_1=web – This is our query and in this case we searched for the term “web”
submit_apply_filter= – Name/value pair for submit_apply_filter but this time this does not have a value which we can see after the equals sign (=), we see the character ampersand (&)
query=web – Name/value pair for “query” which he had from our keyword search
scope=123456789%2F6 – name/value pair for our collection.
Conversely, we can omit query=web and submit_apply_filter= from our name/value pairs like so: https://urlofmydspace/ir/discover?filtertype_1=title&filter_relational_operator_1=contains&filter_1=web&scope=123456789%2F6 and we still get the same search result.
Now for our search form, below is my search form for DSpace that will put in WordPress or any other application/software that accepts html and javascript.
The meat of the javascript function is appending the name/value pair to the corresponding search filter, for keyword, it’s a simple “scope=123456789/6&query=web” while for the title or author, appending this filtertype_1=title&filter_relational_operator_1=contains&filter_1 and omitting &query=. We instead put that search term/query to filter_1 such that the URL fragment for “title” filter becomes: filtertype_1=title&filter_relational_operator_1=contains&filter_1=web while for the “author” filter filtertype_1=author&filter_relational_operator_1=contains&filter_1=web
.
Here is the complete code for this search form, stylize it accordingly.
Before I end this blog post, I’m thankful for the answers I got from this Stackoverflow question especially from user mplungjan. For fellow IT and/or librarians who have similar use case, I hope this blog post will be of help!
Consider this: You are a librarian in a State University. You deplore the state of your library’s collection because you are trying to resurrect already-condemned books so that you can still add it to your collection. Accreditation in your institution is fast approaching (and this includes your library), that’s why you’re doing this. It’s so hard for you to keep this out-of-date books be part of your collection but due to budget constraint, you have to! You even asked the help of librarian friends for donations blessed enough of their libraries. For your institution’s Integrated Library System (ILS), you are lucky enough to be set up with Free and open source software – a fully featured one, hence, you are paying less for the maintenance and set up of your ILS. Then one day, you are able to come out with a Request for Quotation/Canvass for an ILS amounting to Php750,000.00. Talk about priorities! That amount can easily be used to procure more recent books for your library and institution for the use of the students. If you are listening to local radio station Love Radio Manila wherein a “lolo” blurbs some contradicting statements of usual day-to-day life and at the end of the commercial, he ends his punchline with “Di ko ma-konek!”. Indeed, this situation abovementioned – I cannot connect! (“Di ko makonek”).
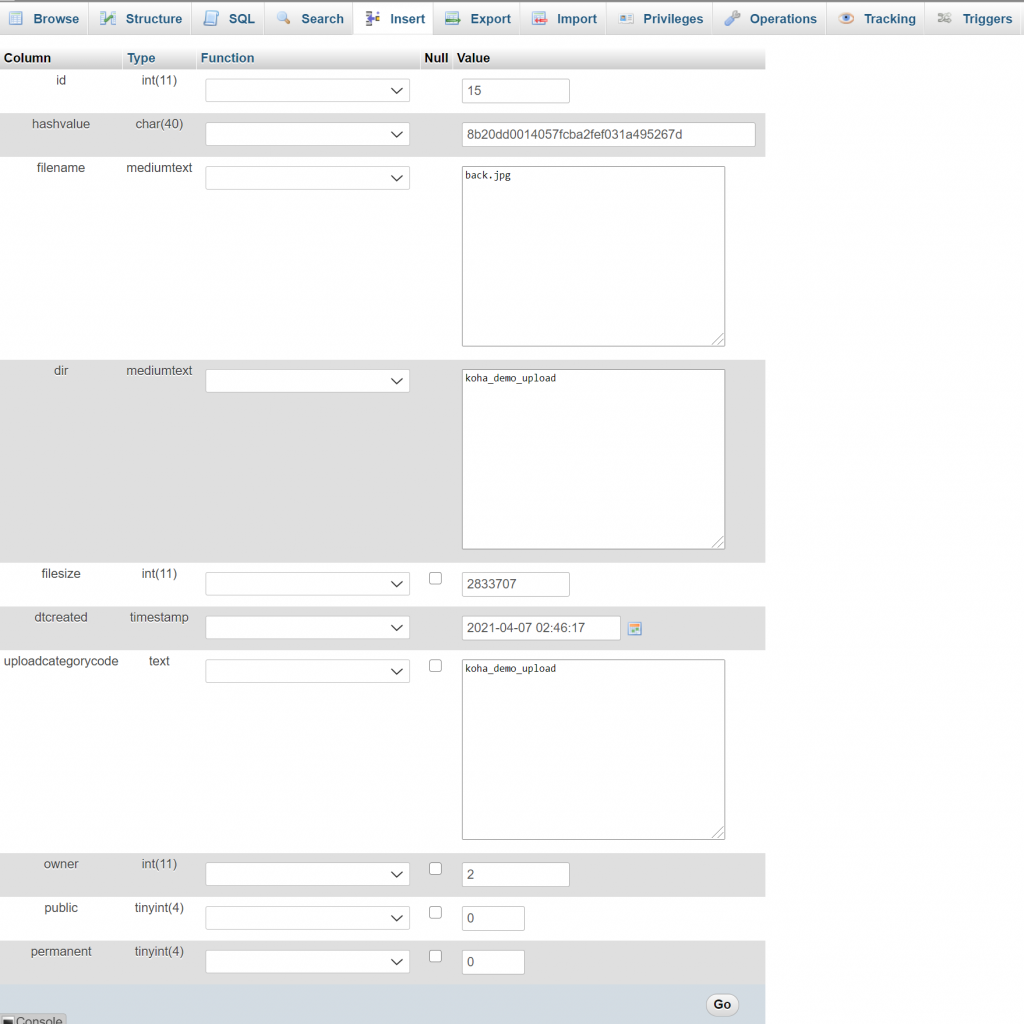
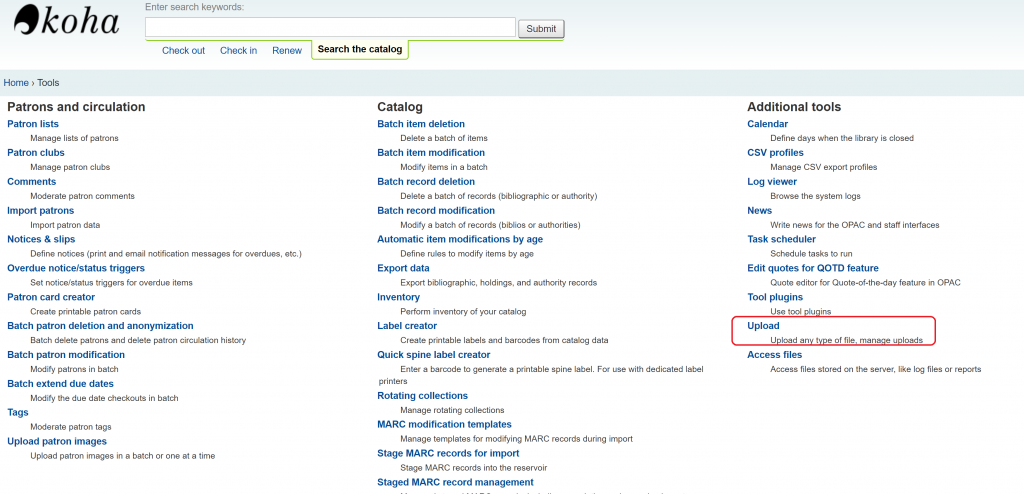
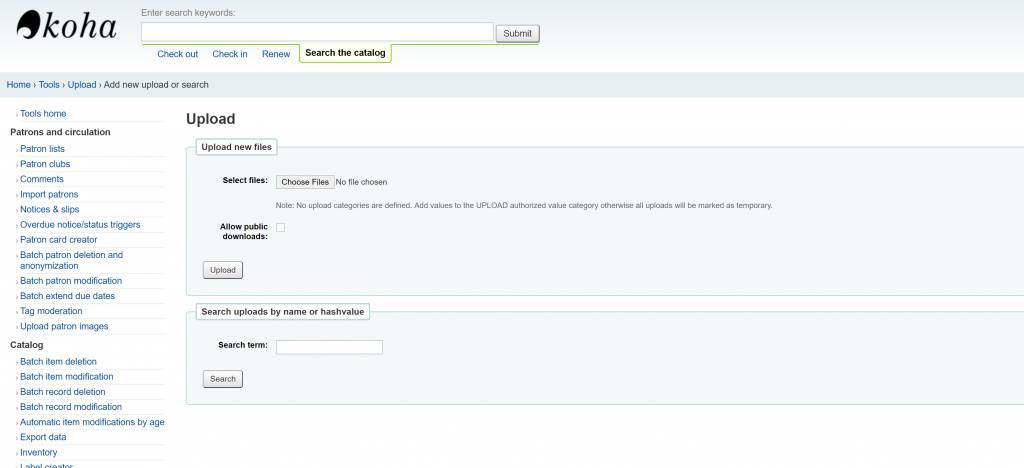
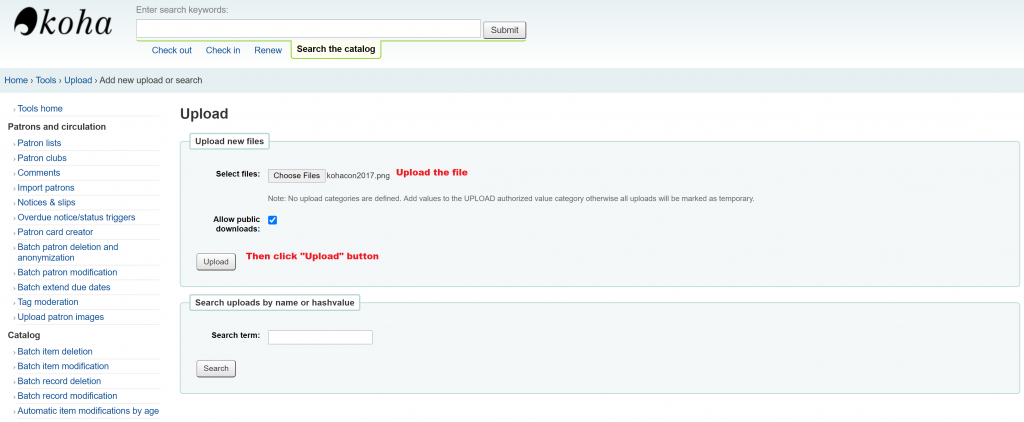
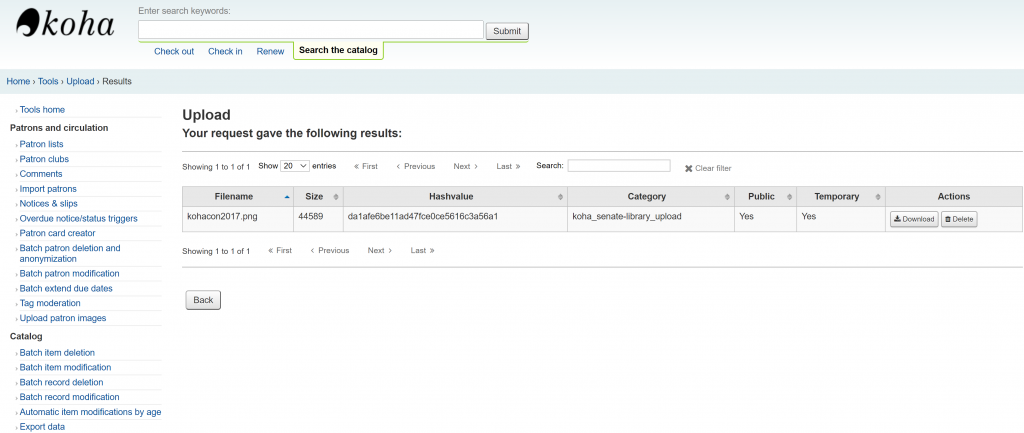
During the last Koha ILS Users Philippines Google Meet (July 18, 2020), Geffy Pen from University of Rizal System asked during the Google meet if we can refer image sources from Google Drive when editing various OPAC Global System Preferences like opacheader and OPACMainUserblock. I honestly does not have an answer to it as I haven’t tried referencing images in Google Drive when customizing the Koha ILS OPAC. I instead answered her to just instead upload the image file (jpg, png, etc.) into Koha ILS via Tools > Upload any file (/cgi-bin/koha/tools/upload.pl). Uploading any files has been in Koha ILS for quite some time (3.22 released November 2015). Using this way to refer to uploaded files will ease any migration nightmares since the uploaded file is already included in the Koha ILS backup mechanism. Note though that to be able to upload this module, there is a need to tweak the Koha ILS instance’s configuration, you can refer to the blog of our friend from India Vimal to be able to enable this (following nos. 1-4). For the procedure on how to go on the with the process, please see images below.
Take note that “Allow public downloads” should be checked or else this particular file we are uploading won’t show up if we call it via “img src” later. As of 19.11.x, we won’t be able to change the setting for allow public downloads
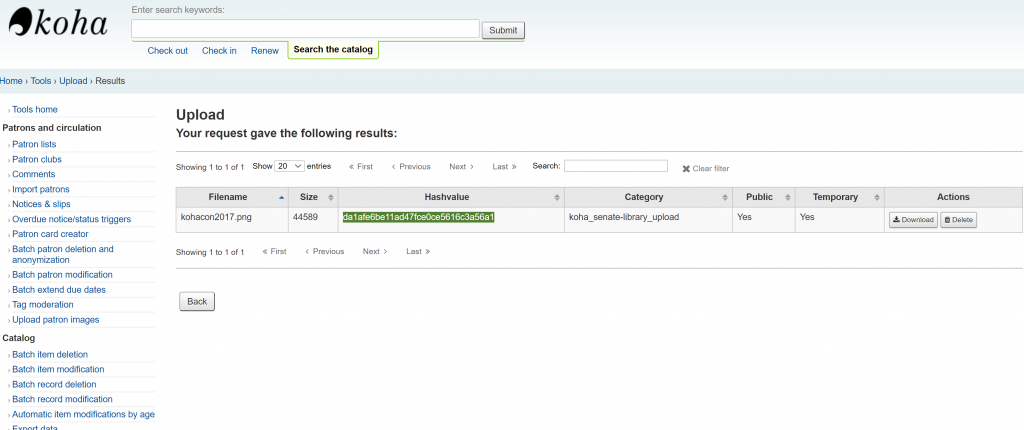
Once uploaded, we will be presented with a page similar below. What we’re interested here is the hashvalue, which we will append to “/cgi-bin/koha/opac-retrieve.pl?id=”.
So for our particular case, we have a relative URL “/cgi-bin/koha/opac-retrieve-file.pl?id=da1afe6be11ad47fce0ce5616c3a56a1” which is what we will add to image source html tag <img src>. We can now reference this image by the following html tag:
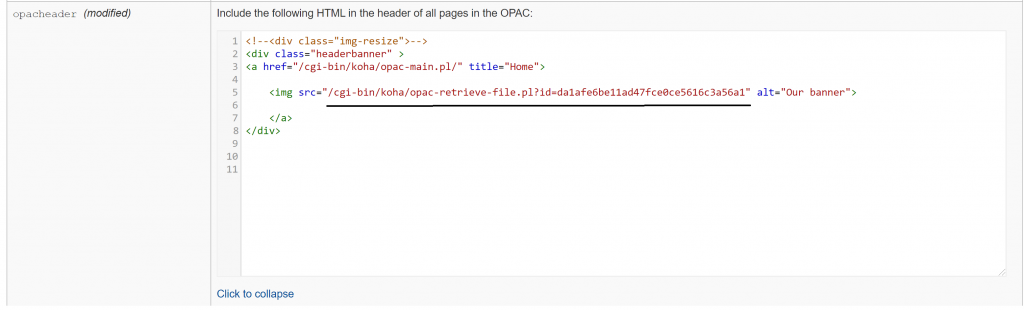
We can add this this into our html codes for further customization of our OPAC, in my example below, Koha ILS’s opacheader.
Save our OPAC preferences, and voila! Our uploaded big banner is now there in our opacheader or banner.
You can certainly upload a banner that fits your library but for the purpose of demonstration, I uploaded a big banner for this exercise.
If your library is uploading various images into the web server through FTP (File Transfer Protocol), you can use this method instead. As I’ve mentioned above, what we’ve uploaded through Koha upload (any) files could have been taken care of by Koha ILS default backup and restoring backups through koha default command will be a breeze.
Yes! Hello World! This is my first post and this post is about a nifty Php script which I was able to update the code/s to work with Php version 7.x. I have been constantly bugging a fellow librarian working in SEAFDEC Library not named Stephen Alayon. I’m not gonna mention his name because he is a shy guy and does not want to be in the limelight, but he is my go-to-guy when it comes to DSpace. Anyway, as gratitude to various buggings I’ve done to him in the past, I updated the code base of a post about a Php script for protecting multiple downloads using unique URLs. This Php script lets a sharer protect a download (or digital product) by generating a unique URL that can be distributed to authorized users via email. Additionally, this Php script masks the true file name of the record to be shared in the file system directory. The URL would contain a key that would be valid for a certain amount of time and number of downloads. The key will become invalid once the first of the conditions is exceeded. The idea is that distributing the unique URL will limit unauthorized downloads resulting from the sharing of legitimate download links. This is what the SEAFDEC Library is using when a researcher asks for copies of copyrighted materials. When a request for copyrighted materials is sent to the library, they open the program, find the corresponding file being requested, and then a URL is created that will be shared to the requestor. And that link would only be valid for seven day and once filed is retrieved, the file would be removed from the document request site (The last part I got from testing the request form of the Library IR). I guess they have been using it for quite some time or since they started using DSpace Institutional Repository.
How it works
The “how it works” aspect of this script can be found in the original post in https://ardamis.com/here and I am copy-pasting it below.
There are five main components to this system:
the MySQL database that holds each key, the key creation time, and the number of times the key has been used
the downloadkey.php page that generates the unique keys and corresponding URLs
the download.php page that accepts the key, verifies its validity, and either initiates the download or rejects the key as invalid
a dbconnect.php file that contains the link to the database and which is included into both of the other PHP files
the download .zip file that is to be protected
Place all three PHP scripts and the .zip file into the same directory on your server.
The MySQL database
Create a new MySQL database named “download” or whatever name but be sure to adjust it accordingly in the php code. Below is the mysql database command to add the table.
CREATE TABLE `downloadkeys` (
`uniqueid` varchar(12) NOT NULL default '',
`timestamp` INT UNSIGNED,
`lifetime` INT UNSIGNED,
`maxdownloads` SMALLINT UNSIGNED,
`downloads` SMALLINT UNSIGNED default '0',
`filename` varchar(60) NOT NULL default '',
`note` varchar(255) NOT NULL default '',
PRIMARY KEY (uniqueid)
);
Original post type for timestamp is INTEGER UNSIGNED with a length of “10”. For similar type from previous projects, I use TIMESTAMP type for timestamp. I did not touch this one because basing from the php source code it indeed uses the date function as “Seconds since the Unix Epoch”.
$time = date('U')
And if I do changed the type for timestamp, the code will break or I have to adjust the code accordingly. Since I want to be able to use this wonderful code in a jiffy, I did not change this part.
The downloadkey.php page
This page is where you generate the keys – the URL of what you will be sharing to your (outside) researchers or to those who want to have a copy of a file you want to share. This is the icing in the pudding. This is where we start all our workflows. As posted in by the original poster in https://ardamis.com/2008/06/11/protecting-a-download-using-a-unique-url/:
Never give out the location of this page – this is for only you to access.
So to be able to hide this page, you can rename downloadkey.php to whatever name you want it called. Below is the downloadkey.php page source code.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Download Key Generator</title>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<meta name="author" content="Oliver Baty | http://www.ardamis.com/" />
<style type="text/css">
#wrapper {
font: 15px Verdana, Arial, Helvetica, sans-serif;
margin: 40px 100px 0 100px;
}
.box {
border: 1px solid #e5e5e5;
padding: 6px;
background: #f5f5f5;
}
input {
font-size: 1em;
}
select {
min-height: 22px;
min-width: 179px;
}
#submit {
padding: 4px 8px;
}
</style>
</head>
<body>
<div id="wrapper">
<h2>Download Key Generator</h2>
<!-- add a count of keys created and downloads to date -->
<?php
error_reporting(1);
require ('config.php');
$link=mysqli_connect($db_host,$db_username,$db_password)
or die ("Could not connect to database");
mysqli_select_db($link,$db_name) or die ("Error");
$keys = htmlspecialchars($_POST['keys'], ENT_QUOTES);
$successkeys = 0;
?>
<?php if(is_numeric($keys) && $_POST['filename'] != "") {
if($keys > 20) { $keys = 20; }
// echo $keys;
// A script to generate unique download keys for the purpose of protecting downloadable goods
if(empty($_SERVER['REQUEST_URI'])) {
$_SERVER['REQUEST_URI'] = $_SERVER['SCRIPT_NAME'];
}
// Strip off query string so dirname() doesn't get confused
$url = preg_replace('/\?.*$/', '', $_SERVER['REQUEST_URI']);
$folderpath = 'http://'.$_SERVER['HTTP_HOST'].'/'.ltrim(dirname($url), '/').'/';
// Strip slashes if necessary
if (get_magic_quotes_gpc()) {
$filename = trim(stripslashes($_POST['filename']));
$maxdownloads = trim(stripslashes($_POST['maxdownloads']));
$lifetime = trim(stripslashes($_POST['lifetime']));
$note = trim(stripslashes($_POST['note']));
} else {
$filename = trim($_POST['filename']);
$maxdownloads = trim($_POST['maxdownloads']);
$lifetime = trim($_POST['lifetime']);
$note = trim($_POST['note']);
}
// Get the activation time
$time = date('U');
// echo "time: " . $time . "<br />";
echo '<div class="box">';
for ($counter = 1; $counter <= $keys; $counter += 1) {
// Generate the unique download key
$key = substr(uniqid(md5(rand())), 0, 12);
// echo "key: " . $key . "<br />";
// Generate the link
echo $folderpath . "download.php?id=" . $key . "<br />\n";
// Sanitize the query
$query = sprintf("INSERT INTO downloadkeys (uniqueid,timestamp,lifetime,maxdownloads,downloads,filename,note) VALUES('$key','$time','%d','%d','%d','%s','%s')",
$lifetime,
$maxdownloads,
0,
mysqli_real_escape_string($link,$filename),
mysqli_real_escape_string($link,$note));
// Write the key and other information to the DB as a new row
$registerid = mysqli_query($link,$query) or die(mysqli_error());
$successkeys++;
}
echo '</div>';
}
?>
<?php if($keys && !$_POST['filename']) { echo '<h2>You must supply a filename for the download.</h2>'; } ?>
<?php if(!$keys) {
if($realfilenames != "") {
$the_filenames = explode(',', $realfilenames);
}
?>
<form action="<?php echo $_SERVER['PHP_SELF']; ?>" id="keyform" method="post">
<table cellpadding="2">
<tr>
<td>Number of keys to generate</td>
<td><input type="text" name="keys" id="keys" value="1" size="20" tabindex="1" /></td>
<td>(maximum of 20)</td>
</tr>
<tr>
<td>File to be downloaded</td>
<?php if($the_filenames) {
echo '<td><select name="filename" id="filename" tabindex="2">';
foreach($the_filenames as $filename) {
echo '<option value="' . $filename . '">' . $filename . '</option>' . "\n";
}
echo '</select></td>' . "\n";
}else{
echo '<td><input type="text" name="filename" id="filename" value="'. $realfilenames . '" size="20" tabindex="2" /></td>';
} ?>
<td>(required)</td>
</tr>
<tr>
<td>Max allowable number of downloads</td>
<td><input type="text" name="maxdownloads" id="maxdownloads" value="<?php echo $maxdownloads; ?>" size="20" tabindex="3" /></td>
<td>(default = <?php echo $maxdownloads; ?>)</td>
</tr>
<tr>
<td>Max age for download key, in seconds</td>
<td><input type="text" name="lifetime" id="lifetime" value="<?php echo $lifetime; ?>" size="20" tabindex="4" /></td>
<td>(default = <?php echo $lifetime; ?> seconds)</td>
</tr>
<tr>
<td>Note</td>
<td><input type="text" name="note" id="note" value="" size="20" tabindex="5" /></td>
<td>(optional)</td>
</tr>
<tr>
<td></td>
<td><input type="submit" id="submit" value="Generate Keys" tabindex="6" /></td>
<td></td>
</tr>
</table>
</form>
<?php } ?>
<p><?php if($successkeys > 0) { echo $successkeys . ' keys successfully created. Click to <a href="' . $_SERVER['PHP_SELF'] . '">create more keys</a>.'; } ?> </p>
<?php if($successkeys == 0) { ?>
<p>Use this page to generate up to 20 unique download keys at a time and save them to the database. The default values for max allowable downloads and max age are set in config.php. See that file for more details.</p>
<p>The note is optional and will be attached to each key, if multiple keys are created. (For example, if you generate 5 keys, the same note will be attached to each of those 5 keys.)</p>
<p>The download links can be copied and pasted into emails or whatever to allow the recipient access to the download.</p>
<p>Each key will be valid for a certain amount of time and number of downloads. The key will no longer be usable when the first condition is exceeded.</p>
<p>The download page has been written to force the browser to begin the download immediately. This will prevent the user of the key from discovering the location of the actual download file.</p>
<?php } ?>
<p>You can also <a href="report.php">generate a report</a> of all keys created so far. (This might time out if you've generated thousands of keys.)</p>
<p style="padding-top:40px;">Brought to you by <a href="http://www.ardamis.com/2009/06/26/protecting-multiple-downloads-using-unique-urls/">ardamis</a>.</p>
</div>
</body>
</html>
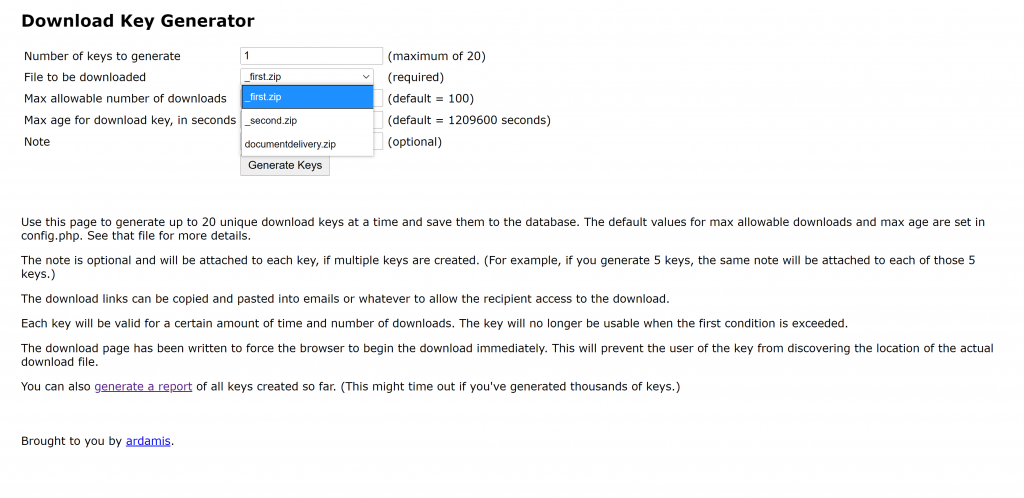
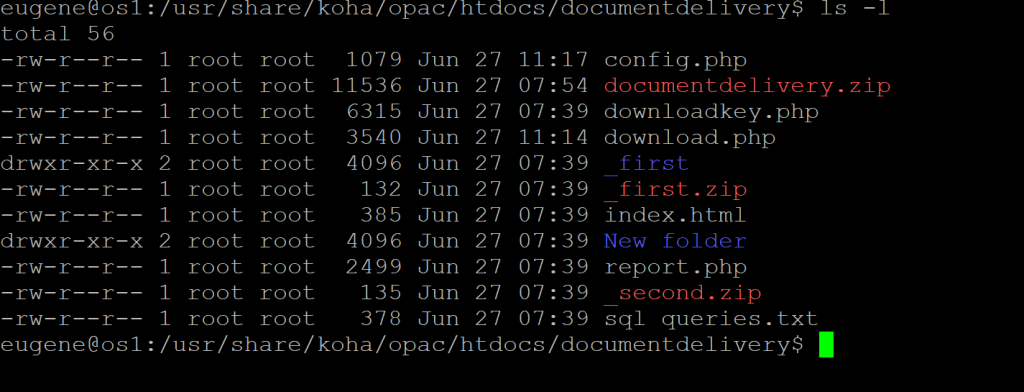
Before we proceed to download.php page, I would like to reiterate that the files you want to share must reside within the directory of the downloadkey.php and that file should be zipped or in zip file. But, there is a way to instead reference them from another directory and to be able to add other file types like .pdf, .xlsx, etc. however, that is not a part of this write-up. See the images below.
You will see from the above images that I have documentdelivery.zip, _first
The URL generated by downloadkey.php points to this page. It contains the key validation script and then forces the browser to begin the download if it finds the key is valid.
The key takeaway from this code is the conversion of mysql code into mysqli since PHP7 has removed the Mysql extension. Using the MySQLi procedural methods, there are some changes in the positions of link. Below is the code for the download.php page.
<?php
error_reporting(1);
require ('config.php');
$link=mysqli_connect($db_host,$db_username,$db_password)
or die ("Could not connect to second database");
mysqli_select_db($link,$db_name) or die ("Error");
$fakefilename = "download.zip";
// GET the unique key
if(get_magic_quotes_gpc()) {
$id = stripslashes($_GET['id']);
}else{
$id = $_GET['id'];
}
//echo $id;
// Reduce it to 12 characters, because a legit key is exactly 12 characters
$id = substr(trim($id), 0, 12);
// Check for tables
$query = "SHOW TABLES FROM $db_name";
$result = mysqli_query($link,$query);
if (!$result) {
echo 'The database is not correctly configured. No tables were found in the database.';
exit;
}
// Check for the downloadkeys table
$query = "SELECT * FROM downloadkeys LIMIT 1";
$result = mysqli_query($link,$query);
if (!$result) {
echo 'The database is not correctly configured. Check the name of the table.';
exit;
}
// Query the database for a match to the key
$query = sprintf("SELECT * FROM downloadkeys WHERE uniqueid = '%s'",
mysqli_real_escape_string($link, $id));
$result = mysqli_query($link,$query) or die(mysqli_error());
//print $result;
// Write the result to an array
$row = mysqli_fetch_array($result);
#print $row[0];
// Begin checking validity of the key
if (mysqli_num_rows($result) == 0) {
// If no match is found, return an error message and exit
echo 'The download key you are using is invalid.';
exit;
}else{
// Calculate the age of the key
$age = date('U') - $row['timestamp'];
$lifetime = $row['lifetime'];
// Compare the age of the key against the allowed age
if ($age >= $lifetime) {
// The key is too old, so exit
echo 'This key has expired (exceeded time allotted).';
exit;
}else{
// The valid key has not expired, so check the number of downloads
$downloads = $row['downloads'];
$maxdownloads = $row['maxdownloads'];
if ($downloads >= $maxdownloads) {
// The number of downloads meets (or exceeds) the allowed number of downloads, so exit
echo 'This key has expired (exceeded allowed downloads).';
exit;
}else{
// The key has passed all validation checks
// Retrieve the filename of the download
$realfilename = $row['filename'];
echo $realfilename;
//echo $fakefilename;
// Increment the download counter
$downloads += 1;
$sql = sprintf("UPDATE downloadkeys SET downloads = '" . $downloads . "' WHERE uniqueid = '%s'",
mysqli_real_escape_string($link, $id));
$incrementdownloads = mysqli_query($link,$sql) or die(mysqli_error());
// Debug echo "Key validated.";
// Force the browser to start the download automatically
// Consider http://www.php.net/manual/en/function.header.php#86554 for problems with large downloads
header('Content-Description: File Transfer');
header('Content-Type: application/octet-stream');
header('Content-Disposition: attachment; filename="' . basename($fakefilename) . '"');
header('Content-Transfer-Encoding: binary');
header('Expires: 0');
header('Cache-Control: must-revalidate');
header('Pragma: public');
//header('Content-Length: ' . filesize($realfilename));
header('Content-Length: ' . filesize($realfilename));
ob_clean();
flush();
readfile($realfilename);
exit;
}
}
}
?>
The config.php script (database connection)
This is the database connection configuration. You need to edit this file to reflect your database connections. The part with the replace ‘db_username’ with the correct database username, ‘db_password’ with the password of used by db_username and ‘db_name’ with the name of your database.
<?php
// Variables:
// Database
$db_host = 'localhost'; // Hostname of database
$db_username = 'db_username'; // Username
$db_password = 'db_password'; // Password
$db_name = 'db_name'; // Database name
// Set the maximum number of downloads (actually, the number of page loads)
$maxdownloads = "2";
// Set the keys' viable duration in seconds (86400 seconds = 24 hours)
$lifetime = "86400";
// Set the real names of actual download files on the server as a comma-separated list (this is optional; you can use a single filename or just leave it as empty double-quotes: "")
$realfilenames = "_first.zip, _second.zip";
// Set the name of local download file - this is what the visitor's file will actually be called when he/she saves it
$fakefilename = "bogus_download_name.zip";
// Connect:
// Connect to the MySQL database using: hostname, username, password
//$link = mysqli_connect($db_host, $db_username, $db_password) or die("Could not connect: " . mysqli_error());
//mysqli_select_db($link,$db_name) or die(mysqli_error());
?>
That’s it, you now have a working platform to give someone access to the download. Visit the downloadkey.php page and generate a unique key code, saved into the database, and a URL is printed out that you can copy and paste into an email or to whatever you want it to be shared (e.g. social media). You can see below it in action, in a gif file below.