Just the other day, I was trying out Selenium for a project I am doing for the Senate Library. Since I was having a hard time curl-ing lists of URLs and consequently automating download of certain parts of html files available at the Senate Legis. In this case, Senate Bills available here
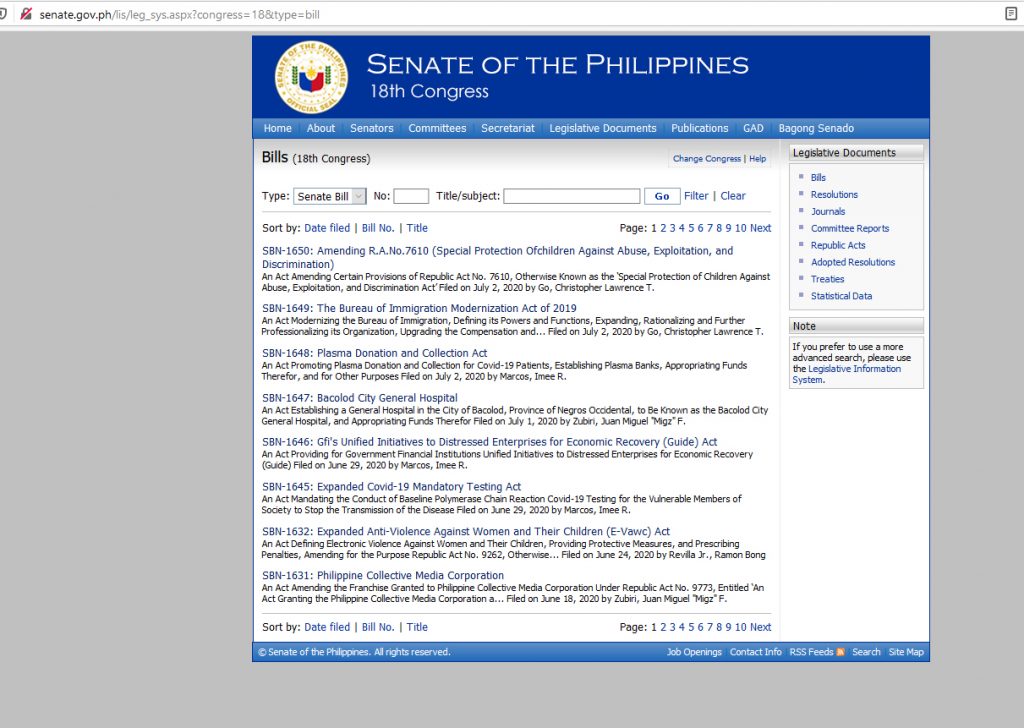
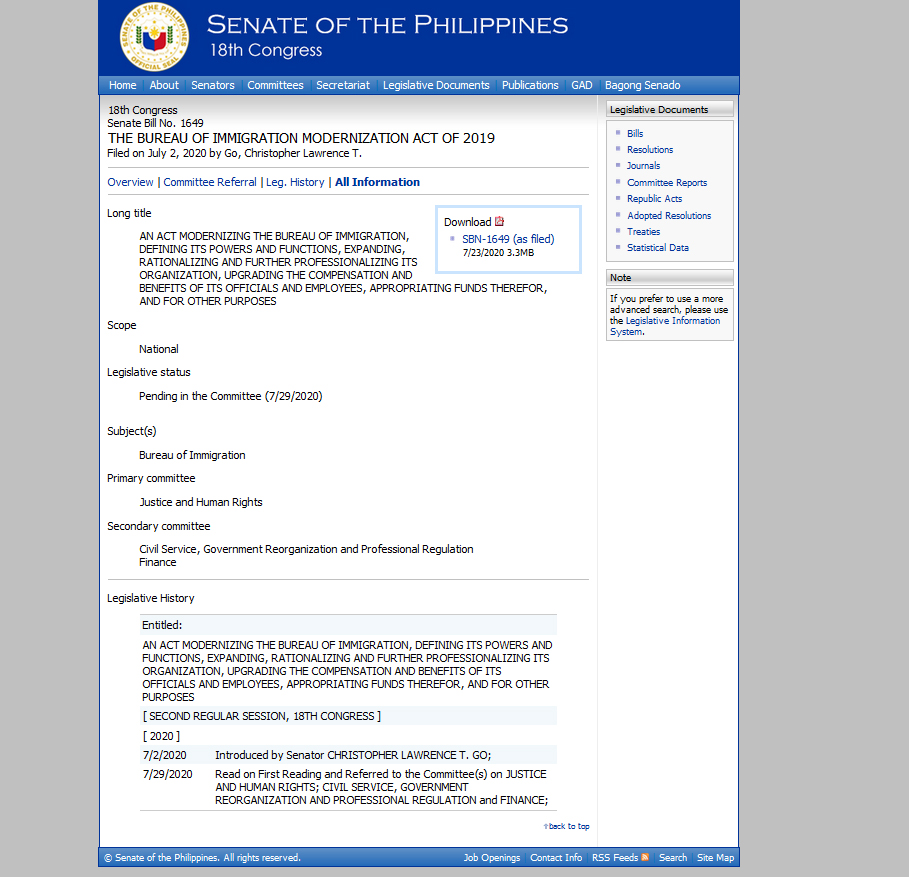
The image above is only the “Overview” of a particular bill, but I am actually more interested in “All Information” which you can see is in the fourth row, just right after Leg. History. As you can see in the image below, it has more information about the Bill and that is what I wanted to capture and repurpose in a different database.
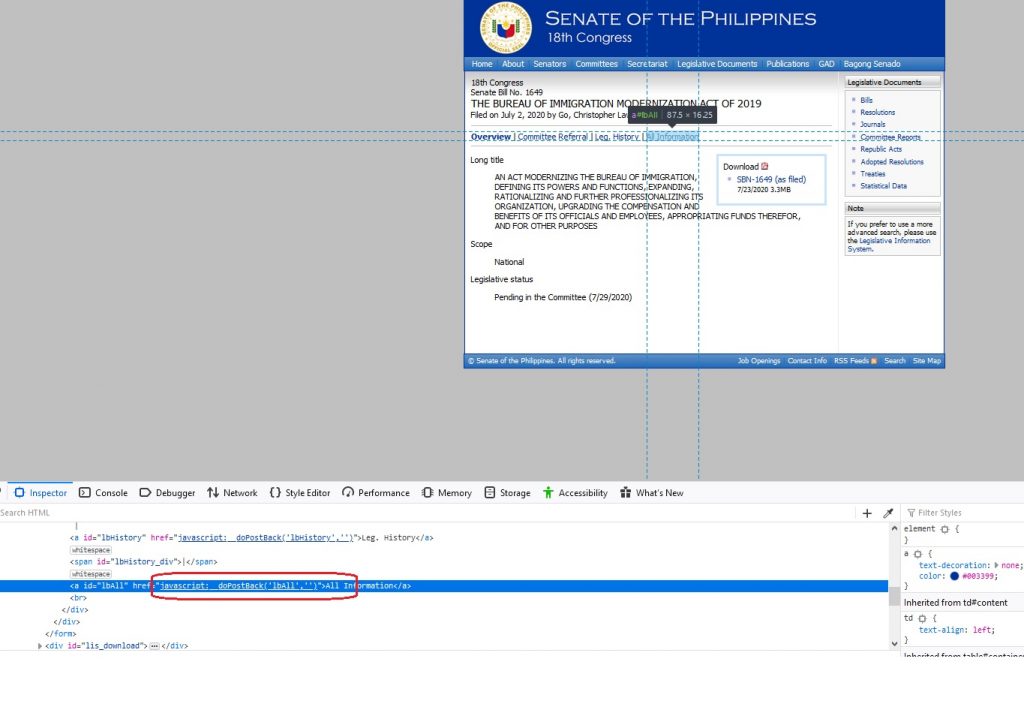
I can actually easily do a perl program with curl that does something like “Go through a list of URLs, after which the program goes to the “All Information Link” and lastly download the html file that includes all web elements in “All Information”. However, there was a problem. Apparently, the link for “All Information” is controlled by a javascript. After researching on how to go about this, apparently I can not do that, and one answer in one stackoverflow question I chance upon suggested using Selenium. And so my adventure with started.
After reading about Selenium and what it can do, I was convinced that this is the way to go about this project. For starters, and based from its main website, Selenium automates browsers.

To get my feet wet, I first tried Browserstack‘s free trial and reading through its documentation on perl, I was able to make it work a small snippet of code from Browserstack. You can see it in action in gif file below.
But the problem with Browserstack is that the free trial is only good for 100 minutes. I have 12670 URLs to run through and three accounts with 100 minutes each (for a total of 300 minutes) won’t make the cut. So, what I did is try to install Selenium in a server*. There is this easy install Selenium available in github created by ziadoz so for the Selenium stack that’s what I installed. I also installed Selenium::Remote::Server module so that I can use selenium for Perl but first installation of this module was not breeze and I cannot remember how I was able to successfully install this module, a separate blog will be created instead on this.
After so many failed tries on the working Perl code courtesy of Browserstack, of which I adjusted for my local installation of Selenium, I came across this github: https://gist.github.com/dnmfarrell/5dde6d3957bf9ae037e170cdb44f75a5 and saw this lines:
extra_capabilities => { chromeOptions => {args => [ qw(window-size=1920,1080 no-sandbox headless allow-running-insecure-content disable-infobars) ]}},Only then did I realize that the chrome that I should be trying to run for my perl script should be headless since I am using a headless server. My Selenium server as well as the Chrome driver starts properly in the command line. I adjusted the variables in my perl file and I was getting sorts of error. And the last error that I had was like below:
Could not create new session: unknown error: Chrome failed to start: exited abnormally.
(unknown error: DevToolsActivePort file doesn't exist)
(The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.)
Lo and behold after adjusting my code and added that chrome option headless did my script run properly.
*Full installation procedure to be posted in a separate blog.